- These general semantic segmentation methods mainly focus on multi-scale context modeling, ignoring the special issues in the HSR remote sensing imagery, such as false alarms and foreground-background imbalance. This causes that these methods are lack of explicit modeling for the foreground.
文章提到现有的语义分割方法主要关注多尺度语义建模,忽视了高分辨率遥感图像上前景和背景不平衡导致的误检,所以这篇文章提出了上图的方法
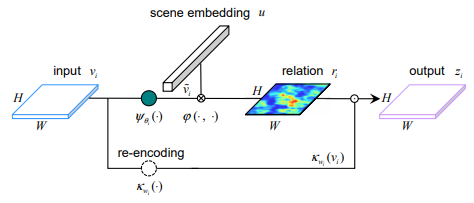
- Apart from the pyramidal feature maps vi, a extrabranch is attached on C5 to generate a geospatial scene feature C6 via global context aggregation. For simplicity, we use global average pooling as the aggregation function. C6 is used to model the relation between geospatial scene and foreground
主要思想就是学了一个场景的embedding:$u$,这个$u$是通过resnet作为backbone提到的特征
$C_{5}$(维度$ H × W × d_{u} $)全局池化得到的一个$ d_{u} $维向量,对于每个位置$i(row,col)$的前景概率计算:$ $r_{i}= \varphi(u,\widetilde{v_{i}})=u和\widetilde{v_{i}}的内积$
那么相当于学了一个$d_{u}$维空间里区分前景和背景的基$u$,如果是前景,则$r_{i}$在空间中越靠近$u$这个基所在的方向上,内积响应更大,也就是$r(H×W)$中更红的位置
下面那一路$k_{w_{i}}(v_{i})$只是一个1×1卷积+Relu 重新对$v_{i}$特征做了一次非线性变换 维度$ H × W × d_{u} 到 H × W × d_{u} $。
$z_{i}=\frac{1}{1+exp(-r_{i})}×k_{w_{i}}(v_{i})$ 那么刚刚算的$r_{i}\in[0,1]$越大(越接近于1)保留的特征越多,$r_{i}$越小(越接近于0)保留的特征越少,保留的特征范围在$[0.5×k_{w_{i}}(v_{i}),\frac{e}{e+1}×k_{w_{i}}(v_{i})]$



