CVPR2020 Geometric Adversarial Attacks and Defenses on 3D Point Clouds
摘要
深度神经网络很容易出现恶意攻击,这些攻击会恶意更改网络的结果。在这项工作中,我们从几何角度探索对抗性例子。 也就是说,对源点云的微小更改在通过自动编码器模型后会导致来自其他目标类的形状。在防御方面,我们表明,在将防御应用于对抗输入之后,重构后的输出中仍会存在攻击目标形状的残留物。
攻击

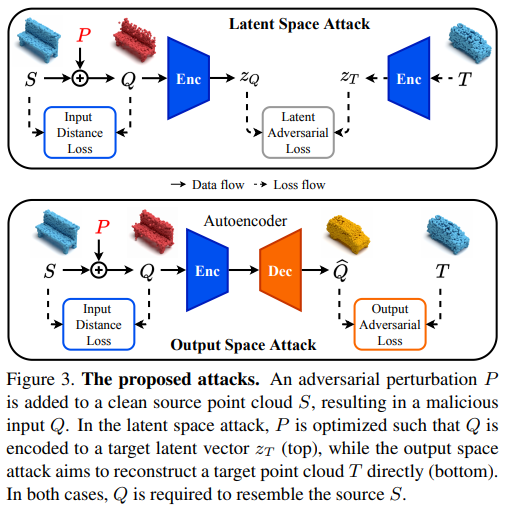
如上图所示,通过学习一个扰动$P=\delta x_{椅子}$使得$autoencoder$对加了扰动后的椅子点云$Q=S+P$重建为车,$f(x_{椅子} + \delta x_{椅子})=f(x_{椅子} + P)=f(S+P)=f(Q)=x_{车}$,
主要看2个$loss$
第1个$loss$
让加了扰动后的椅子点云$Q$与目标车点云$T$经过$autoencoder$中间编码的隐特征越近越好,同时要保持扰动后的椅子和扰动前的椅子相差不大,这里的$loss$都是欧式距离
第2个$loss$
让加了扰动后的椅子点云经过$autoencoder$后的重建点云$\hat{Q}$与目标车点云$T$越近越好,同时要保持扰动后的椅子和扰动前的椅子相差不大,这里的$loss$都是欧式距离
防御
防御措施是在编码器端,在恶意输入点云上进行的。使输入中的对抗点偏离,以抵消攻击对重构输出的影响。 我们提出两种防御措施。
1.依靠点云中的最近邻居统计信息来删除表面外的点。 这种防御不基于被攻击的$autoencoder$。
去除表面上的点
在清洁点集中,一个点通常在形状的表面上具有邻近点。 相反,对抗性输入可能具有表面外的点。
算一个点和临近点的平均距离,如果超过阈值说明它是不在正常曲面上的点而是攻击后扰动的点,就删去
2.基于被攻击的$autoencoder$。 确定出导致对抗性重建的关键点并过滤掉它们
对抗性扰动将点移动到使$autoencoder$输出所需目标形状的位置。 基于PointNet,学一个网络识别出影响$autoencoder$潜在向量的关键点。将他们滤掉后 同时对这些关键点位置进行补齐,从而减少了攻击对重建点云的影响。 将此防御的结果点云表示为$Q_{comp}^{def}$。



